DeepSeek R1 and the Rise of Reasoning Models: System 2 AI Goes Open Source
The release of DeepSeek R1 has democratized 'System 2' reasoning capabilities previously locked behind closed APIs. We analyze how test-time compute and chain-of-thought distillation are redefining open-source AI performance.

For most of the generative AI boom, “open source” meant “almost as good as GPT-4, but faster.” Models like Llama 3 and Mistral excelled at standard tasks but crumbled when asked to solve novel math problems or debug obfuscated code. That changed in late 2025 with the release of DeepSeek R1, the first open-weights model to effectively implement “System 2” thinking—deliberate, step-by-step reasoning that rivals OpenAI’s o1-series.
This shift marks a critical bifurcation in AI architecture: avoiding the race for larger parameters (System 1) in favor of scaling test-time compute (System 2). Here is why DeepSeek R1 changes the trajectory of enterprise AI.
System 1 vs. System 2 in AI
Nobel laureate Daniel Kahneman defined human cognition in two modes:
- System 1: Fast, instinctive, automatic. (e.g., “What is 2+2?” -> “4”)
- System 2: Slow, corrective, logical. (e.g., “Calculate 17 x 24” -> “10 x 24 is 240… 7 x 20 is 140… 7 x 4 is 28… sum is 408”)
Traditional LLMs (GPT-4, Claude 3.5 Sonnet) are pure System 1. They generate the next token immediately based on statistical likelihood. They don’t “think”—they reflexively predict.
Reasoning Models (o1, R1) introduce a “hidden” chain-of-thought process before outputting the final answer. When asked a complex physics question, the model effectively talks to itself: “Let me try approach A… wait, that violates conservation of energy. Let me backtrack and try approach B…” This internal monologue allows it to self-correct logic errors that would otherwise hallucinate.
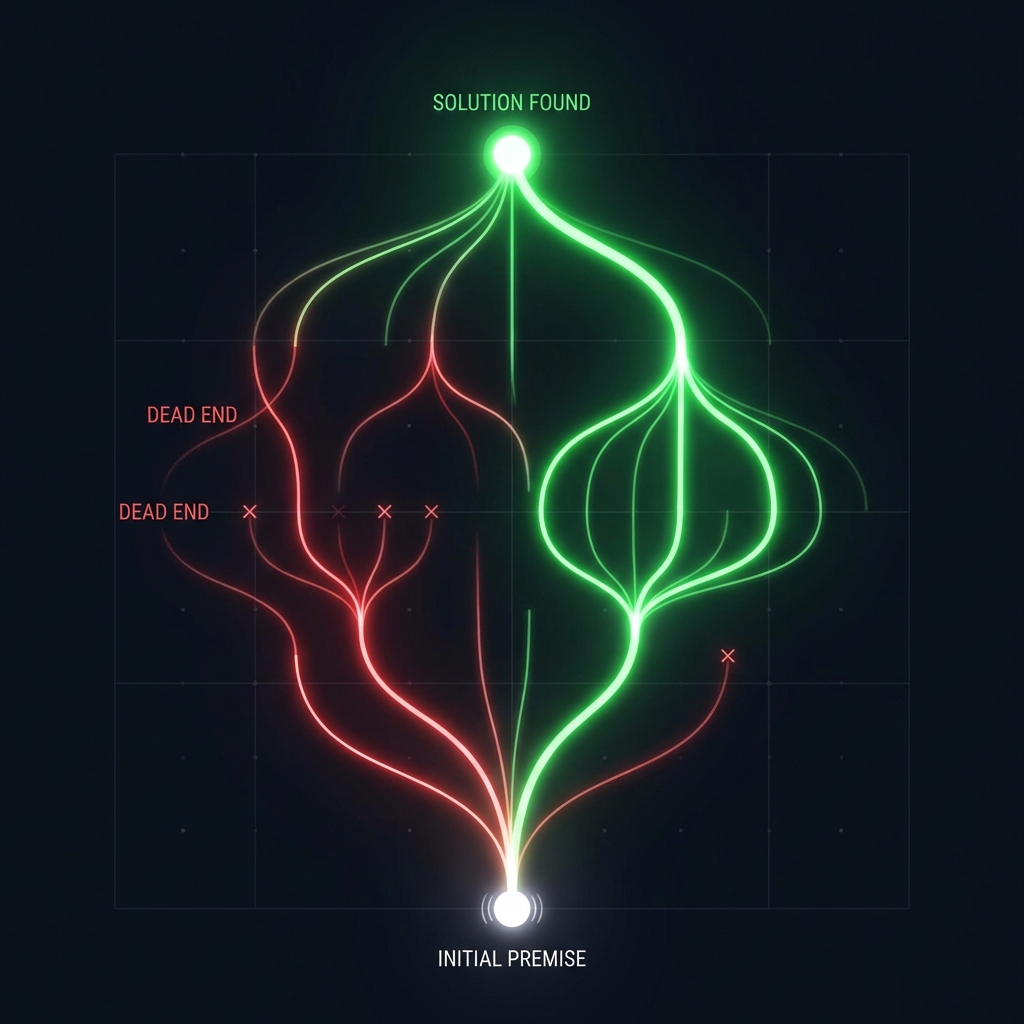
The DeepSeek R1 Architecture
DeepSeek R1 achieves this through two novel methods:
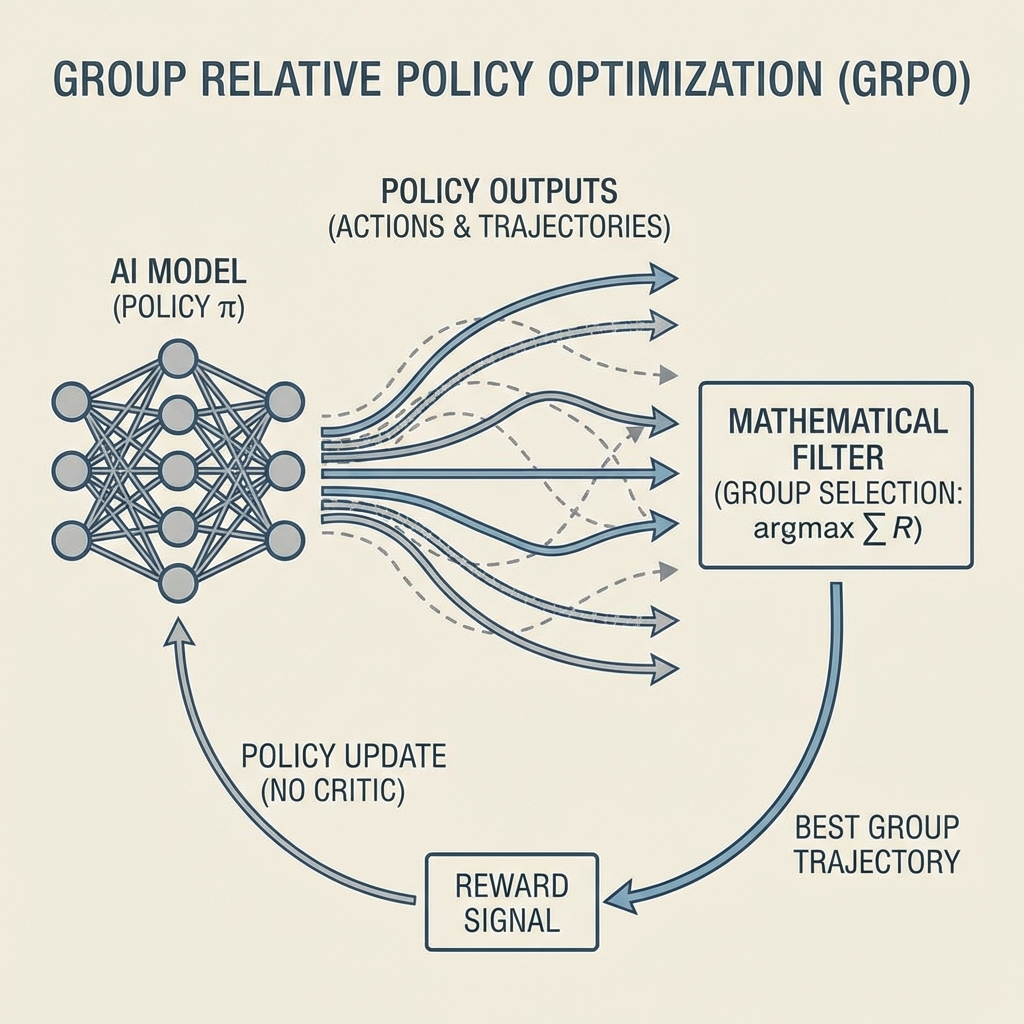
1. Group Relative Policy Optimization (GRPO)
Previous reinforcement learning (RLHF) required a “Critic” model to score every answer—a computationally expensive bottleneck. DeepSeek removed the critic. Instead, GRPO generates a group of distinct reasoning paths for the same prompt and optimizes based on the relative quality of the group. If 3 out of 10 paths lead to the correct math answer, the model reinforces the reasoning steps that produced those 3, without needing an external truth model to grade every intermediate step.
2. Large-Scale Distillation
Training a massive reasoning model from scratch is prohibitively expensive. DeepSeek proved that reasoning patterns can be distilled. They trained a massive “Teacher” model using pure RL, then used its high-quality chain-of-thought outputs to fine-tune smaller “Student” models (7B, 14B parameters). The result? A 14B parameter model that outperforms 70B parameter density models on math benchmarks (MATH-500) because it knows how to think, not just facts.

Benchmark Performance: The Open Source Flip
In standardized tests, DeepSeek R1-Zero (the base model) shocked the industry:
- AIME 2024 (Math Competitions): Scored 79.8%, matching OpenAI o1-preview and crushing GPT-4o (9%).
- Codeforces (Programming): Achieved 96th percentile, solving algorithmic problems that baffle standard coding assistants.
- Cost Efficiency: Training R1 cost roughly $6 Million in compute—a fraction of the estimated $100M+ for leading frontier models, proving that algorithmic efficiency (GRPO) beats brute force scaling.
Enterprise Implications
Why does an open-weight reasoning model matter for business?
1. Private Reasoning on Premise Banks and healthcare providers couldn’t use cloud-based reasoning models (o1) for sensitive data due to privacy laws. DeepSeek R1 can be quantized and run on local GPU clusters (e.g., 8x H100s). A hospital can now run a System 2 diagnostic agent on patient records entirely offline.
2. The End of “Prompt Engineering” With standard LLMs, users had to manually guide the model: “Think step by step, check your work, be careful.” Reasoning models internalize this. The model effectively prompt-engineers itself during the inference chain, reducing the need for complex user prompting strategies.
3. Distillation for Vertical Agents Enterprises is now taking the open-weight R1, generating thousands of reasoning traces for their specific domain (e.g., semiconductor design rules), and distilling a tiny, hyper-specialized 8B model that creates chip layouts better than a general-purpose giant.
Conclusion
DeepSeek R1 proves that “reasoning” is not a moat protected by trillion-dollar infrastructure. By demonstrating that reinforcement learning can induce emergent critical thinking in open models, DeepSeek has accelerated the commoditization of intelligence. For growing engineering teams, the strategy for 2026 is clear: use simple models for text generation, but route complex logic tasks to specialized reasoning models—which you can now own, host, and control.
Related Articles

The Commoditization of Intelligence: How Open Source Won the AI War
The gap between proprietary giants (GPT-5) and open weights (Llama 4, Mistral) has vanished. We analyze why 85% of enterprises are moving workloads to self-hosted models and what this means for the economics of AI.

The New RAG Stack: Why Retrieval-Augmented Generation is Evolving in 2026
Simple vector search is no longer enough. Discover how RAG 2.0 architectures integrate Knowledge Graphs, hybrid search (BM25 + Dense), and agentic reasoning to solve the 'lost in the middle' problem and deliver production-grade accuracy.

The AI Arms Race: Cybersecurity in the Age of Autonomous Agents
When phishers use voice clones and malware writes itself, traditional firewalls are useless. We explore the 2026 threat landscape: hyper-personalized social engineering, automated penetration testing, and the Zero Trust AI response.