The New RAG Stack: Why Retrieval-Augmented Generation is Evolving in 2026
Simple vector search is no longer enough. Discover how RAG 2.0 architectures integrate Knowledge Graphs, hybrid search (BM25 + Dense), and agentic reasoning to solve the 'lost in the middle' problem and deliver production-grade accuracy.

In 2024, “chat with your PDF” was a magic trick. By 2026, Retrieval-Augmented Generation (RAG) has become the backbone of enterprise AI, solving the two fatal flaws of standalone LLMs: hallucinations and knowledge cutoffs. But the “naive RAG” stack—chunking text, embedding it, and performing cosine similarity search—is dying. It failed at multi-hop reasoning (“Compare the revenue growth of our Asian division in Q3 versus the European division in Q2”) and global summarization (“What are the main themes in these 5,000 legal contracts?”).
The industry has shifted to RAG 2.0: hybrid architectures combining vector search with Knowledge Graphs (GraphRAG), semantic reranking, and agentic retrieval strategies. This analysis details the production stack delivering 98% retrieval accuracy for Fortune 500 trailblazers.
Why Naive RAG Failed at Scale
First-generation RAG systems operated on a simple premise: semantic proximity equals relevance. If you asked about “apple revenue,” the system fetched chunks containing similar words. This approach collapsed under three conditions:
- The “Lost in the Middle” Phenomenon: When an answer required synthesizing information from the beginning, middle, and end of a 50-page document, simple top-k retrieval often missed the connecting context.
 2. Vocabulary Mismatch: A user searching for “turnover” might miss documents discussing “churn” or “attrition” if the embedding model wasn’t finely tuned for that specific domain.
3. Structured Data Blindness: Dense vector embeddings struggle to capture precise relationships in structured data (SQL, tabular CSVs). Asking “Which customers bought Product X and had support tickets last week?” is a relational query that purely semantic search flunks.
2. Vocabulary Mismatch: A user searching for “turnover” might miss documents discussing “churn” or “attrition” if the embedding model wasn’t finely tuned for that specific domain.
3. Structured Data Blindness: Dense vector embeddings struggle to capture precise relationships in structured data (SQL, tabular CSVs). Asking “Which customers bought Product X and had support tickets last week?” is a relational query that purely semantic search flunks.
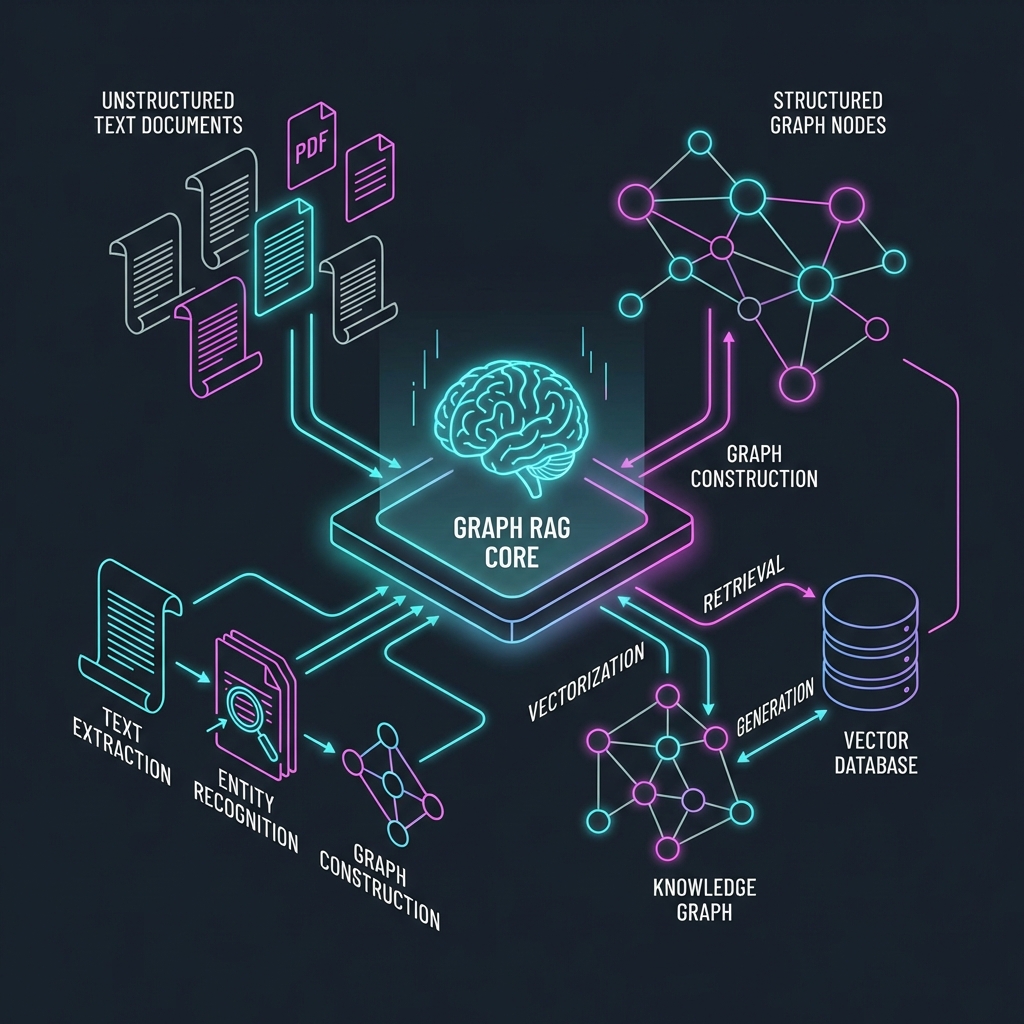
The Solution: GraphRAG and Hybrid Search
1. GraphRAG: Structuring the Unstructured
Microsoft Research’s GraphRAG approach, mainstreamed in late 2025, extracts entities (people, places, concepts) and relationships from text before embedding them. It builds a Knowledge Graph where “Elon Musk” is a node connected to “Tesla” (CEO of) and “SpaceX” (Founder of).
When a query comes in, the system doesn’t just look for matching words; it traverses the graph.
- Query: “How did supply chain delays affect our Q3 margins?”
- Naive RAG: Finds chunks mentioning “supply chain” and “margins.” might miss the causal link hidden in a separate supplier email.
- GraphRAG: Identifies the “Supply Chain” node, follows the “caused” edge to “Late Delivery,” which links to “Production Halt,” which links to “Reduced Margins.” It retrieves the reasoning path, not just keyword matches.
Performance Impact: Early adopters report a 40-60% improvement in answer quality for complex, multi-document queries compared to baseline vector search.
2. Hybrid Search (Sparse + Dense)
Vector search (Dense) is great for concepts; Keyword search (Sparse/BM25) is unbeatable for exact matches (part numbers, error codes, unique names). The modern stack uses Hybrid Search: running both BM25 and Vector search in parallel, then utilizing Reciprocal Rank Fusion (RRF) to merge the results.
- Example: Searching for “Error code 0x80244019 network timeout.”
- Vector search focuses on “network timeout” concepts.
- Keyword search nails the exact error code “0x80244019”.
- Hybrid result guarantees the technical precision of keywords with the conceptual understanding of vectors.
The Production RAG Stack for 2026
If you are building an enterprise knowledge engine today, this is the reference architecture:
- Ingestion & ETL: Unstructured data (PDF, HTML) is cleaned. LayoutLM models preserve document structure (headers, tables) rather than flattening everything into plain text.
- Chunking Strategy: “Semantic Chunking” replaces fixed-size windows. Chunks are broken at logical boundaries (new topic, new section) determined by a small NLP model, not arbitrary character counts.
- Indexing (The “Triple Store” approach):
- Vector Store: (e.g., Pinecone, Weaviate) for semantic search.
- Keyword Index: (e.g., Elasticsearch, BM25) for exact match.
- Graph Store: (e.g., Neo4j, AuraDB) for relationship mapping.
 4. Retrieval & Reranking:
* Retrieve top 50 candidates from Hybrid Search.
* Pass them through a Cross-Encoder Reranker (like Cohere Rerank 3). This computationally expensive model scores every candidate pair against the query for relevance, reordering the list.
* Pass the top 5 to the LLM.
5. Generation: The LLM (GPT-4o, Claude 3.5) synthesizes the answer, citing specific chunks as footnotes.
4. Retrieval & Reranking:
* Retrieve top 50 candidates from Hybrid Search.
* Pass them through a Cross-Encoder Reranker (like Cohere Rerank 3). This computationally expensive model scores every candidate pair against the query for relevance, reordering the list.
* Pass the top 5 to the LLM.
5. Generation: The LLM (GPT-4o, Claude 3.5) synthesizes the answer, citing specific chunks as footnotes.
Case Study: Legal Tech Firm “LexAutomata”
Challenge: Lawyers needed to query 100,000 distinct case files to find “precedent for maritime liability in international waters.” Naive RAG Failure: Returned random maritime cases but missed subtle jurisdictional nuances. GraphRAG Solution:
- built a graph linking “Case” -> “Judge” -> “Ruling” -> “Citied Precedent”.
- Queries could now ask: “Find cases where Judge Smith cited the ‘1982 Convention’ negatively.”
- Result: 94% retrieval accuracy vs 68% baseline.
Future Outlook: Agentic RAG
The next leap is Agentic RAG. Instead of a single retrieval step, the system becomes an agent.
- User: “Write a report comparing our AI budget to our competitors.”
- Agent: “I need internal budget data.” -> Queries internal vector store.
- Agent: “Now I need competitor data.” -> Searches web (Google/Perplexity API).
- Agent: “I found the data, but the currencies don’t match.” -> Uses Calculator tool to normalize to USD.
- Agent: Writes final answer.
This autonomous loop—query, critique, refine, query again—transforms RAG from a search engine into a research analyst.
Key Takeaways
- Stop doing simple RAG for mission-critical apps. It’s a prototype architecture.
- Invest in Reranking: It is the single highest-ROI upgrade for retrieval quality.
- Structure your data: Garbage in, garbage out. GraphRAG proves that defining relationships matters more than just raw text volume.
- Hybrid is mandatory: Don’t throw away keyword search; combine it with vectors for robustness.
Related Articles

DeepSeek R1 and the Rise of Reasoning Models: System 2 AI Goes Open Source
The release of DeepSeek R1 has democratized 'System 2' reasoning capabilities previously locked behind closed APIs. We analyze how test-time compute and chain-of-thought distillation are redefining open-source AI performance.

The AI Arms Race: Cybersecurity in the Age of Autonomous Agents
When phishers use voice clones and malware writes itself, traditional firewalls are useless. We explore the 2026 threat landscape: hyper-personalized social engineering, automated penetration testing, and the Zero Trust AI response.

Intelligence at the Edge: Running LLMs on Phones, Cars, and Toasters
The Cloud is too slow and too expensive. The next frontier is Edge AI—running 3B parameter models directly on your smartphone. We explore NPU hardware, 4-bit quantization, and the privacy revolution.